
티스토리 뷰
JdbcTemplate의 Batch Insert 구현시, rewriteBatchedStatements 옵션을 true로 설정하여 성능 문제 해결
DevHyo 2021. 4. 17. 21:10Spring Batch Application과 JPA, JDBC를 함께 사용하여 Batch 작업을 처리해야 하는 상황이 있었습니다. 이때 MySQL Connector/J (JDBC Reference) - Configuration Properties for Connector/J 에서 제공하는 기능들을 몰랐기에, 원하는 대로 동작하지 않았던 문제가 있었습니다.
문제 상황 (예시)
데이터를 가공해서 1,000 ~ 150,000개의 데이터를 Pay 테이블에 넣어야 하는 상황이었습니다. MySQL을 사용하는 상황이었고, JPA의 IDENTITY 방식으로 Batch Insert를 활용하기에는 성능적으로 좋지 않은 부분들이 있었습니다. 이를 해결하기 위해서 JdbcTemplate의 batchUpdate를 활용해서 Batch Insert를 구현했고, Insert 쿼리가 합쳐진 형태로 실행될 거라 예상했습니다. 그러나 예상과는 다르게 JpaRepository의 saveAll 메소드와 직접 구현한 PayJdbcRepository의 saveAll 메소드의 수행 시간을 측정한 결과, 같은 수행 시간으로 처리되는 것을 확인했습니다.
Pay 엔티티
@Entity
class Pay(amount: Long, txName: String, txDateTime: String) {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null
@Column(nullable = false)
var amount: Long = amount
protected set
@Column(nullable = false)
var txName: String = txName
protected set
@Column(nullable = false)
var txDateTime: LocalDateTime = LocalDateTime.parse(txDateTime, FORMATTER)
protected set
fun setamount (amount: Long) {
this.amount = amount
}
fun settxName (txName: String) {
this.txName = txName
}
fun settxDateTime (txDateTime: LocalDateTime) {
this.txDateTime = txDateTime
}
override fun toString() = kotlinToString(properties = toStringProperties)
override fun equals(other: Any?) = kotlinEquals(other = other, properties = equalsAndHashCodeProperties)
override fun hashCode() = kotlinHashCode(properties = equalsAndHashCodeProperties)
companion object {
private val FORMATTER: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
private val equalsAndHashCodeProperties = arrayOf(Pay::id)
private val toStringProperties = arrayOf(
Pay::id,
Pay::amount,
Pay::txName,
Pay::txDateTime,
)
}
}PayRepository (JpaRepository를 상속한 Repository)
interface PayRepository : JpaRepository<Pay, Long>Pay 엔티티를 Batch Insert 처리하기 위한 Jdbc Custom Repository
@Repository
class PayJdbcRepository(
@Value("\${batch-size}")
private val batchSize: Int,
private val jdbcTemplate: JdbcTemplate
) {
private val logger: Logger = LoggerFactory.getLogger(this.javaClass)
fun saveAll(entityList: MutableList<Pay>) {
val subEntityList: MutableList<Pay> = mutableListOf()
var batchCount = 0
for (i in 0 until entityList.size) {
subEntityList.add(entityList[i])
if ((i + 1) % batchSize == 0) {
batchCount = batchInsert(batchCount, subEntityList)
}
}
if (subEntityList.isNotEmpty()) {
batchCount = batchInsert(batchCount, subEntityList)
}
logger.info("Entity total size = {}", entityList.size)
logger.info("Entity batch count = {}", batchCount)
}
private fun batchInsert(batchCount: Int, subEntityList: MutableList<Pay>): Int {
val bulkInsertQuery = "INSERT INTO pay (amount, tx_name, tx_date_time) VALUES (?, ?, ?)"
jdbcTemplate.batchUpdate(bulkInsertQuery, object : BatchPreparedStatementSetter {
override fun setValues(preparedStatement: PreparedStatement, index: Int) {
preparedStatement.setLong(1, subEntityList[index].amount)
preparedStatement.setString(2, subEntityList[index].txName)
preparedStatement.setTimestamp(3, Timestamp.valueOf(subEntityList[index].txDateTime))
}
override fun getBatchSize(): Int {
return subEntityList.size
}
})
subEntityList.clear()
return batchCount + 1
}
}수행 시간을 측정하기 위한 테스트 코드
@SpringBootTest(classes = [TestBatchConfig::class, PayJdbcRepository::class])
@ActiveProfiles(value = ["mysql"])
class PayRepositoryTest {
private val dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
@Autowired
private lateinit var payRepository: PayRepository
@Autowired
private lateinit var payJdbcRepository: PayJdbcRepository
@Test
fun `payRepository의 saveAll 메소드 수행 시간을 측정한다`() {
val pays: MutableList<Pay> = mutableListOf()
for (i in 0 until 1000) {
pays.add(Pay(amount = 100L, txName = "pay_$i", txDateTime = LocalDateTime.now().format(dateTimeFormatter)))
}
val startTime = System.currentTimeMillis()
payRepository.saveAll(pays)
val endTime = System.currentTimeMillis()
println("execution time = " + (endTime - startTime) + "ms")
}
@Test
fun `payJdbcRepository의 saveAll 메소드 수행 시간을 측정한다`() {
val pays: MutableList<Pay> = mutableListOf()
for (i in 0 until 1000) {
pays.add(Pay(amount = 100L, txName = "pay_$i", txDateTime = LocalDateTime.now().format(dateTimeFormatter)))
}
val startTime = System.currentTimeMillis()
payJdbcRepository.saveAll(pays)
val endTime = System.currentTimeMillis()
println("execution time = " + (endTime - startTime) + "ms")
}
}위의 코드와 테스트 코드를 작성하여 수행 시간을 측정하려고 했고, 당연히 JpaRepository의 saveAll로 처리되는 시간보다 PayJdbcRepository의 saveAll로 처리되는 시간이 당연히 빠를 거라 생각하고 있었습니다. 이렇게 생각한 이유는 PayJdbcRepository에 구현한 saveAll은 INSERT 쿼리문이 합쳐진 형태로 처리될 거라 생각했기 때문입니다.
INSERT INTO pay (amount, tx_name, tx_date_time)
VALUES (100, 'pay_0', '2021-04-17 10:29:50'),(100, 'pay_1', '2021-04-17 10:29:50') ....우선 1,000개의 데이터를 JpaRepository를 사용하여 saveAll 처리한 결과, 다음과 같이 테스트 총 수행 시간은 3s 76ms, 실제 쿼리가 수행된 시간은 execution time = 2942ms 인 것을 확인할 수 있었습니다. 또한, Insert 쿼리 자체도 개별적으로 실행되고 있었습니다.

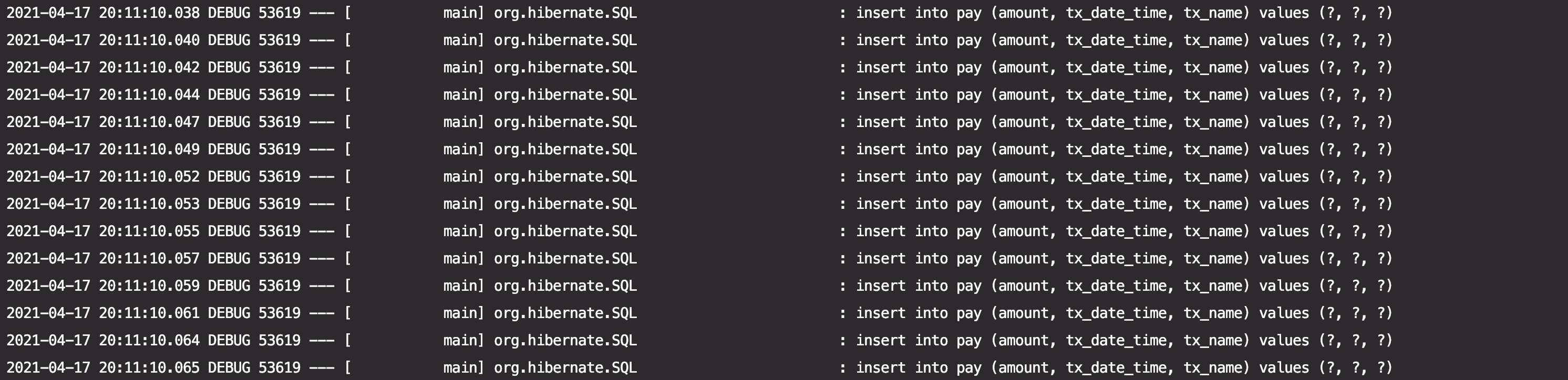
그리고 PayJdbcRepository의 saveAll 방식으로 처리한 결과, 테스트 총 수행 시간은 3s 10ms, 실제 쿼리가 수행된 시간은 execution time = 2873ms 인 것을 확인할 수 있었고, JpaRepository의 saveAll 방식과 차이가 거의 없다는 것을 알게 되었습니다.

위와 같은 결과를 확인 하면서, 처리되는 수행 시간이 왜 비슷할까? JdbcTemplate의 batchUpdate 메소드에 작성한 Insert 쿼리는 어떻게 실행되는 걸까? Insert 쿼리가 개별적으로 실행되는 건가? 여러가지 생각을 하게 되었고, Log를 통해 확인하려고 했습니다. 위에서 언급한 MySQL Connector/J (JDBC Reference) - Configuration Properties for Connector/J 문서와 MySQL 환경의 스프링부트에 하이버네이트 배치 설정 해보기, Hibernate Batch/Bulk Insert/Update 글들을 참고하여, 아래의 application.yml에서 jdbc-url에 옵션들을 추가하고, 쿼리 로그를 확인하려고 했습니다.
application.yml 에서 jdbc-url 변경 전
# 나머지 설정 생략...
datasource:
hikari:
jdbc-url: jdbc:mysql://localhost:9020/db?useSSL=false&characterEncoding=UTF-8
username: ?
password: ?
driver-class-name: com.mysql.cj.jdbc.Driverapplication.yml 에서 jdbc-url 변경 후
- profileSQL : Driver에서 전송하는 쿼리를 출력합니다.
- logger : Driver에서 쿼리 출력시 사용할 Logger를 설정합니다.
- maxQuerySizeToLog : 출력할 쿼리 길이 설정합니다.
# 나머지 설정 생략...
datasource:
hikari:
# 기존 jdbc-url에서 MySQL 쿼리 Log를 확인할 수 있는 profileSQL, profileSQL, maxQuerySizeToLog 옵션을 추가했음.
jdbc-url: jdbc:mysql://localhost:9020/db?useSSL=false&characterEncoding=UTF-8&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=200
username: ?
password: ?
driver-class-name: com.mysql.cj.jdbc.DriverMySQL에서 실제로 수행되는 쿼리를 확인하는 옵션들을 추가한 후, 다시 테스트 코드를 실행했고, Insert 쿼리가 개별적으로 실행되는 것을 확인할 수 있었습니다.

jdbc-url에 rewriteBatchedStatements 옵션을 true로 설정하여, 문제 해결
MySQL Connector/J (JDBC Reference) - Configuration Properties for Connector/J - Performance Extensions 문서와 여러 블로그들을 검색하여 rewriteBatchedStatements=true로 설정하면, 제가 원했던 Insert 쿼리가 합쳐진 형태로 실행된다는 것을 확인할 수 있었고, 바로 옵션을 적용했습니다.
jdbc-url에 rewriteBatchedStatements=true 옵션 추가
- jdbc-url: jdbc:mysql://localhost:9020/db?useSSL=false&characterEncoding=UTF-8&rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=200
테스트 결과, 테스트 총 수행 시간은 249ms, 실제 쿼리가 수행된 시간은 execution time = 100ms인 것을 확인할 수 있었습니다. 정리하자면, rewriteBatchedStatements가 적용되지 않은 경우(false)에는 2s 873ms의 수행 시간이 측정되었는데, rewriteBatchedStatements=true 옵션을 통해 약 28배의 수행 시간이 개선되었음을 확인할 수 있었습니다.

마지막으로 Insert 쿼리의 형태도 합쳐진 Insert 쿼리로 실행 되었음을 확인할 수 있었습니다.

참고
'Dev Log' 카테고리의 다른 글
| Hikari Connection Pool 에서 Connection 획득할 때, 발생했던 DeadLock 해결 (0) | 2022.06.15 |
|---|---|
| 분산 락을 사용하여, 동시성 문제 해결하기 (0) | 2022.05.07 |
| ConnectionAcquireTimeoutError [SequelizeConnectionAcquireTimeoutError]: Operation 해결하기 (2) | 2022.04.27 |
| 동시성을 위한 여러가지 기법 정리 (0) | 2021.09.26 |
| MongoDB 사용시, 인증 기능 설정하기 (0) | 2021.08.03 |