
티스토리 뷰
개인 프로젝트로 SNS 피드 서비스를 개발하면서 팬아웃(포스팅 전송) 기능의 성능을 높이고자 Kotlin의 Coroutine 및 Dispatcher.IO 워커 스레드를 사용하다가 성능 테스트를 통해 OutOfMemoryException을 발견하게 되었고, 이를 해결하고 처리 성능을 높인 경험을 소개하려고 한다.
문제의 발단
일단 팬아웃(포스팅 전송) 기능은 내가 SNS 게시물을 올리면, 나를 팔로우하는 사람에게 피드를 전송하는 기능이다. 그래서 팔로워들은 자신의 피드에서 나의 게시물을 볼 수 있다. 그리고 아키텍처는 다음과 같이 설계했다.

Server에서 Kafka로 Feed 이벤트를 발행할 때, 아래와 같은 로직으로 구현을 했다. 우선 execute 메서드 안에서는 CoroutineScope(Dispatcher.IO). launch를 통해 suspend 함수인 findFollowerAndSendFeed는 Coroutine으로 생성되며, IO 워커 스레드에 의해서 비동기 처리된다.
fun execute() {
// 상위 CoroutineScope
CoroutineScope(context = Dispatchers.IO).launch {
// Redis 관련 작업
setPostCache(id = post.id!!, postCache = post.toPostCache())
setPostViewCount(id = post.id!!, viewCount = post.viewCount)
zaddPostKeys(id = post.id!!, createdAt = post.createdAt)
zremPostKeysRangeByRank()
// 팔로워 조회 후, Kafka에 메시지 발행
findFollowerAndSendFeed(postId, createdAt, followeeId)
}
}findFollowerAndSendFeed 메서드 내부에서는 while문을 통해 나를 팔로우한 사람들을 조회하고, Kafka로 Feed 이벤트를 발행한다. Feed 이벤트를 Kafka 클러스터로 발행할 때, 성능을 높이고자 CoroutineScope(Dispatcher.IO). launch를 추가로 사용했는데, 여기서 OutOfMemoryException이 발생했던 것이다.
private suspend fun findFollowerAndSendFeed(
postId: Long,
createdAt: LocalDateTime,
followeeId: Long,
) {
val limit = 1000L
var offset = 0L
var isProgress = true
while (isProgress) {
val (total: Long, follows: List<Follow>) = findAllByFolloweeIdAndLimitAndOffset(
followeeId = followeeId,
limit = limit,
offset = offset,
)
follows.forEach {
// 여기서 CoroutineScope 를 중첩으로 사용하면 에러가 발생한다.
CoroutineScope(context = Dispatchers.IO).launch {
sendFeedToFollower(postId = postId, createdAt = createdAt, followerId = it.followerId)
}
}
offset += limit
if (offset >= total) {
isProgress = false
}
}
}
private suspend fun findAllByFolloweeIdAndLimitAndOffset(
followeeId: Long,
limit: Long,
offset: Long,
): Pair<Long, List<Follow>> {
// ...
}
private suspend fun sendFeedToFollower(postId: Long, createdAt: LocalDateTime, followerId: Long) {
// ...
}원인 분석
그래서 Heap Dump를 생성시켜, 메모리 분석 툴로 JVM Heap의 상태를 체크했다. Application을 실행시킬 때, -xms, -xmx 옵션 값은 4G로 설정했는데 아래와 같이 3.7GB 중에 알 수 없는 무언가가 2.6GB(69%)를 차지하고 있었다.

아래의 이미지처럼 2가지의 원인이 있었는데, 가장 큰 메모리를 차지하고 있는 Problem Suspect 2 항목을 먼저 확인했다. kotlinx.coroutines.scheduling.CoroutineSchedulers$Worker위치에서 Heap영역에 객체를 생성하는데, GC가 생성한 객체를 수거하지 않는다는 점을 확인할 수 있었다.
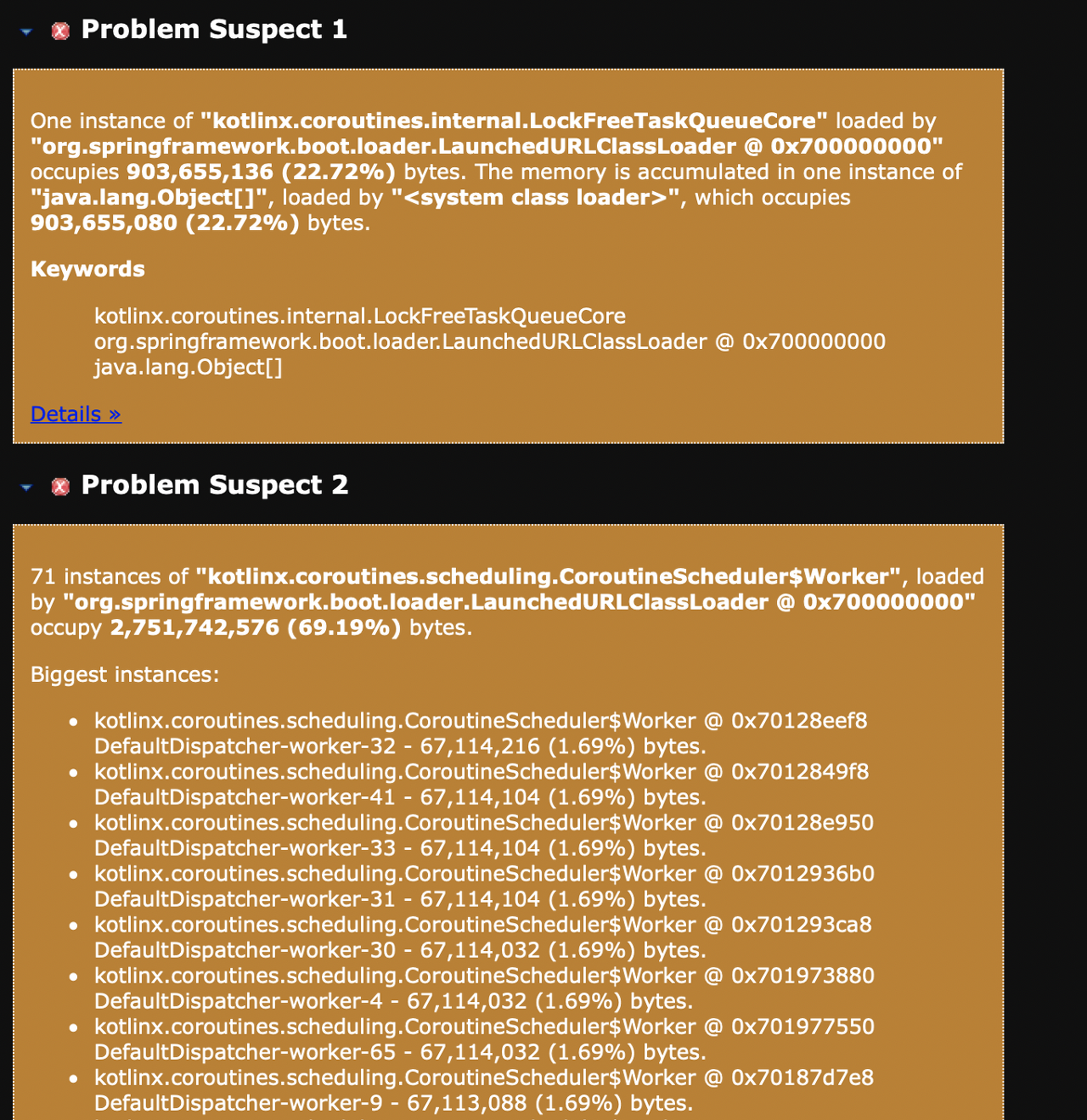
그중에서 67,108,880 Byte를 차지하고 있는 정보를 확인해봤다.

array 객체를 확인해보니 똑같은 DefaultDispatcher-worker-32 Thread 객체를 상위로 올라갈수록 계속 참조하고 있다.

그래서 위의 작성한 코드에서 while문 안에 있는 CoroutineScope(Dispatcher.IO). launch를 제거하고, 다시 돌려봤더니 OutOfMemoryException이 발생하지 않았다.
fun execute() {
// 상위 CoroutineScope
CoroutineScope(context = Dispatchers.IO).launch {
// Redis 관련 작업
setPostCache(id = post.id!!, postCache = post.toPostCache())
setPostViewCount(id = post.id!!, viewCount = post.viewCount)
zaddPostKeys(id = post.id!!, createdAt = post.createdAt)
zremPostKeysRangeByRank()
// 팔로워 조회 후, Kafka에 메시지 발행
findFollowerAndSendFeed(postId, createdAt, followeeId)
}
}
private suspend fun findFollowerAndSendFeed(
postId: Long,
createdAt: LocalDateTime,
followeeId: Long,
) {
val limit = 1000L
var offset = 0L
var isProgress = true
while (isProgress) {
val (total: Long, follows: List<Follow>) = findAllByFolloweeIdAndLimitAndOffset(
followeeId = followeeId,
limit = limit,
offset = offset,
)
follows.forEach {
// CoroutineScope(context = Dispatchers.IO).launch 제거
sendFeedToFollower(postId = postId, createdAt = createdAt, followerId = it.followerId)
}
offset += limit
if (offset >= total) {
isProgress = false
}
}
}
private suspend fun findAllByFolloweeIdAndLimitAndOffset(
followeeId: Long,
limit: Long,
offset: Long,
): Pair<Long, List<Follow>> {
// ...
}
private suspend fun sendFeedToFollower(postId: Long, createdAt: LocalDateTime, followerId: Long) {
// ...
}Nested CoroutineScope
중첩된 CoroutineScope에 초점을 맞추고 이와 관련된 내용들을 검색해봤더니 아래와 같은 글을 통해 문제가 발생한 원인을 찾을 수 있었다.
https://codingwithmohit.com/coroutines/coroutines-job-structure/
Coroutines Job Structures
This article will explore examples of creating Job hierarchies, their effect on cancellation, and Supervisor Jobs.
codingwithmohit.com
해당 링크의 글에서 아래와 같은 예제가 있고 노란색 박스로 주의 사항을 알려주고 있었는데, 요약해보자면 다음과 같다.
val scope1 = CoroutineScope(Dispatchers.IO)
val job = scope.launch {
val scope2 = CoroutineScope(Dispatchers.IO)
scope2.launch { /*...*/ }
val job1 = launch { /*...*/ }
val job2 = launch { /*...*/ }
val job3 = launch { /*...*/ }
}
scope1.cancel()Upon cancellation of scope1, scope2 will not be canceled. It will not affect scope2 as it is a separate coroutine. The coroutine will keep running, and this will cause memory leaks. Being mindful of how your coroutine fits in a hierarchy is essential. It will help you prevent memory leaks.
즉, scope2는 scope1의 영향을 받지 않고 계속 실행되기 때문에 메모리 누수를 일으킬 것이라는 내용이며, 내가 잘 못 사용하고 있었음을 알 수 있었다.
다시 원점으로 돌아가서 생각해 보자
나의 목표는 Feed 이벤트의 발행 성능을 높이는 것이다. 그런데 CoroutineScope를 사용하면 순간적인 성능은 높아지지만 트래픽이 점점 많아지면 결국 OutOfMemoryException이 발생한다. 이로 인해서 사용할 수 없고, Feed 이벤트 발행 성능을 높일 수 없게 되는데 어떻게 처리 성능을 높일 수 있을까?
Kafka Producer 발행 시, 비동기 콜백을 사용해서 처리 성능 높이기
기존의 발행 로직에서는 동기 방식으로 처리가 되고 있었는데, 동기 방식으로 처리된다는 의미는 Kafka Producer가 메시지를 발행하고, Kafka Cluster(Broker)에서 응답이 올 때까지 대기하고(Blocking 상태), 응답이 오면 다음 메시지를 Kafka Cluster로 발행한다. 이러한 과정 때문에 처리 성능이 좋지 않을 수 있다. 비동기 콜백 방식은 Kafka Producer에서 일단 메시지를 보내고, Kafka Cluster에서 응답이 오면 콜백을 통해 응답을 처리한다. 그리고 결과는 다음과 같았다.
| 발행되는 메시지의 수 | 처리 시간 | |
| 동기 방식 | 10,000건 | 17분 |
| 비동기 콜백 방식 | 10,000건 | 2~3초 |
비동기 콜백 방식으로 전환하여, 위와 같은 결과를 얻을 수 있었고 OutOfMemoryException도 더 이상 발생하지 않았다.
정리
메시지 발행 성능을 높이고자 Coroutine 및 Dispatcher.IO 워커 스레드를 활용했는데, 중첩된 CoroutineScope를 사용하면 메모리 누수 발생할 가능성이 높다는 것을 알 수 있었다. 또한 Coroutine 말고도 KafkaProducer에서 제공하는 Future를 통해 비동기 콜백 처리가 가능하다는 것도 알게 되었다. 마지막으로 성능 테스트는 꼭 해야 한다는 것을 느끼게 된 경험이었다.
개인 프로젝트
https://github.com/bestdevhyo1225/large-system-design
GitHub - bestdevhyo1225/large-system-design: Repository for designing large systems
Repository for designing large systems. Contribute to bestdevhyo1225/large-system-design development by creating an account on GitHub.
github.com
'Dev Log' 카테고리의 다른 글
| Hikari Connection Pool 에서 Connection 획득할 때, 발생했던 DeadLock 해결 (0) | 2022.06.15 |
|---|---|
| 분산 락을 사용하여, 동시성 문제 해결하기 (0) | 2022.05.07 |
| ConnectionAcquireTimeoutError [SequelizeConnectionAcquireTimeoutError]: Operation 해결하기 (2) | 2022.04.27 |
| 동시성을 위한 여러가지 기법 정리 (0) | 2021.09.26 |
| MongoDB 사용시, 인증 기능 설정하기 (0) | 2021.08.03 |